近期最火的话题还是AI,连金融市场最火的还是AI以及AI相关的话题,但对于AI到底是什么?包含什么?大部分人是不知道的,如今AI在生活中越来越重要,所以了解下AI相关的知识是有一定必要的,无论是从生活、投资以及使用的角度来说,都有一定的认知帮助。
目前对于绝大部分的人来说接触到的“AI”是指下图中最底层的LLM大语言模型,也被称为大模型,我们常听说的Deepseek、ChatGPT等知名的AI,就在这个层级上,但其实AI是一个非常泛的概念,所以从下图出发,可以来尝试理解下AI相关的概念。
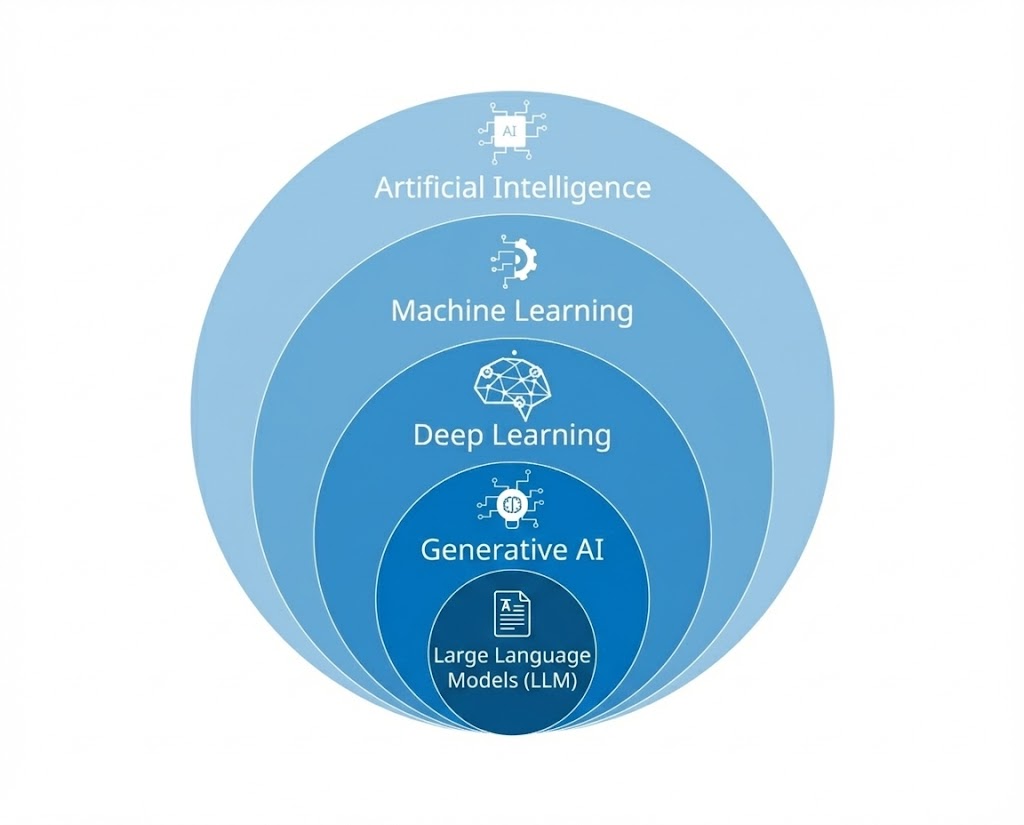
人工智能(AI, Artificial Intelligence)
AI指的是一个非常大的总称,这个词在很早之前就提出来了,泛指一切能够让机器展现智慧的技术都可以被称为“AI”,同时AI这个词并不是一个新词,虽然在最近几年才被大众所知,但实际上由“AI之父”的约翰·麦卡锡(下图)在1956年提出,之所以这么多年没有发展起来,有各种方面的条件不成熟,比如计算机科学中的计算能力就在当时是达不到像目前一样训练这么庞大的数据内容。

同时需要清楚的认识到AI并不是独指计算机科学,而是包含了很多的学科,如数学、心理学、认知科学、神经科学以及哲学等,计算机科学只是实现AI的工具,或者叫载体,可以理解为计算机科学给AI提供了身体,数学给AI提供了大脑,神经科学给AI提供了学习过程(模仿人类大脑神经),心理学和认知科学给AI提供了学习思路(比如奖励学习等)。
如果有AI相关的概念在金融市场中得到了剧烈的反应可能不一定是计算机科学出现了一些突破,所以如果有兴趣可以去研究一下AI相关的科学是否有相关的进步。
机器学习(ML, Machine Learning)

机器学习是AI的一个子集,目的不是为了让机器去通过死记硬背的方式去学习,而是丢一堆数据,让机器去找到数据的规律,比如人类每天都将一天中吃的第一顿饭叫为“早饭”,那么机器就学会了这叫“早饭”,专业上这叫“模式识别”。
同时机器在学习中还会学习到其他的东西,比如“早餐”中经常会出现有一个长条的物体(油条),所以机器学习还会识别到这个食物是早餐食物,这个在专业上被称为“泛化能力”,也就是我们所谓的举一反三。
深度学习(Deep Learning)
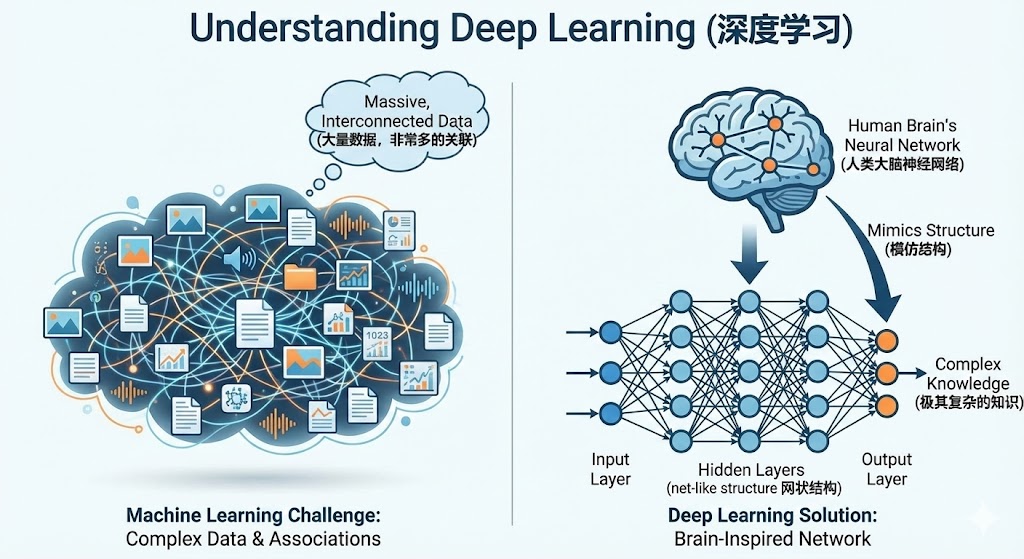
深度学习则指因为机器学习需要使用大量的数据进行学习,并且之间还会有非常多的关联,所以知识应该呈现的是网状结构,而深度学习则是模仿了这样的网状结构,也就是模仿人类大脑的神经网络结构来学习极其复杂的知识。
生成式AI(Generative AI)

生成式AI,指以接受信息数据,根据这些信息数据(指令)生成文本、视频以及图片等的子集,或者深度学习的应用方向之一,我们目前所称的AI大部分集中在这个方向上,包括所谓的Deepseek、GPT以及Gemini等。
大语言模型(LLM, Large Language Model)
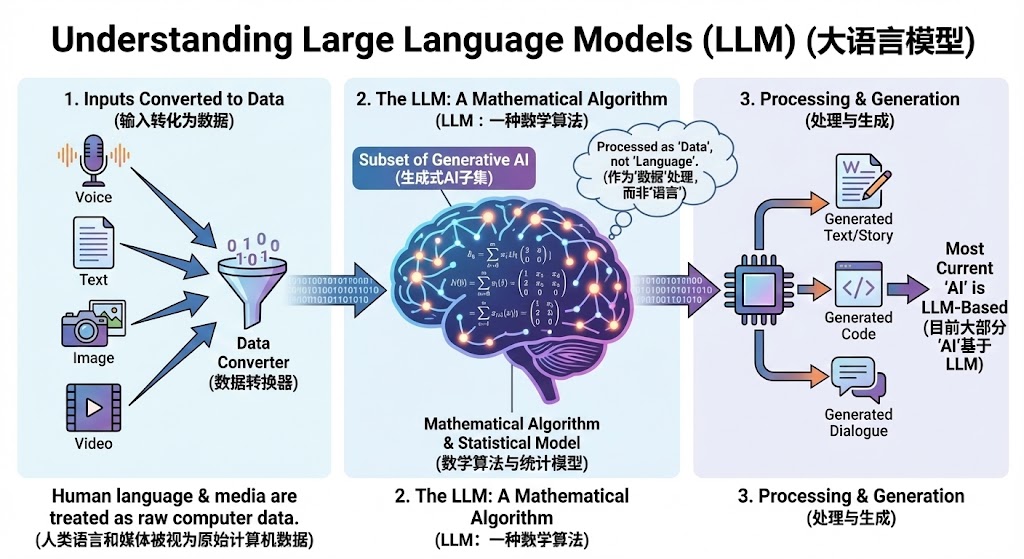
大语言模型,也被称为大模型,实际上就是一种数学算法,名字上虽然有语言,但并不是人类的语言,泛指计算机能理解的语言“数据”,属于生成式AI的一种,一种大规模神经网络,这是因为对于计算机来说,根本不认识我们的文字、语音等,对于计算机来说,这就是一个数据,所以目前我们常接触的大部分“AI”,都是基于LLM,无论是你给的语音、图片还是视频,最终都被转换为了数据传递给LLM进行处理。
上述说完了后,可以分享一些我的见解,比如为什么市面上有这么多AI,他们有什么区别吗?AI解决了什么?为什么需要对AI进行管控?下面依次来说说。
不同的AI有什么区别?
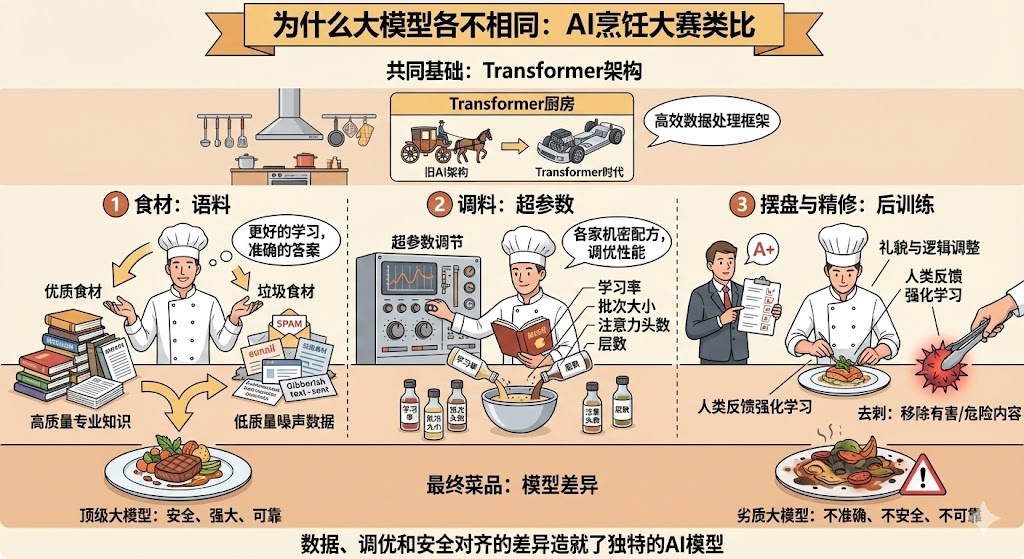
据我所知,目前市面上几乎所有的大模型(LLM)都是基于Google 在2017年发布的Transformer架构,这个架构极大的提高了大语言模型的数据处理、学习的方式,你可以简单理解为以前的AI架构是马车,一个马+两个轮子,而Transformer则是如今的汽车框架,包含四个轮子、发动机以及底盘的高效架构,那么大家架构都是一样的情况下,还有什么是不同的,可以再简单做一个比喻,将做大模型理解为做饭,每个人用食材的不同、调料的调配比不一样以及如何摆盘的区别。
上述中“食材”在专业中被称为“语料”,也就是用于训练大模型的原始数据,不同的数据是能够让大模型学习到不同的知识,同时对于数据的质量也有区别,比如你给大模型学习一堆垃圾数据和让大模型去学习非常专业的论文,给出来的答案是天壤之别的。
上述中“调料的配比”在专业中被称为“超参数”,工程师通过根据不同的参数调节,让语料以及大模型之间得到一个较好的表现,而往往“超参数”就是各家的商业机密,也是商业护城河之一。
上述中“如何摆盘”在专业中被称为“后训练”,工程师通过不停的给大模型打分,让大模型说话更加礼貌以及逻辑严密等,同时会进行一些“去刺”的工作,比如避免让大模型产生一些危险的回答,比如教人如何制作炸弹等非常危险的回答。
所以如上这些区别可以简单的理解为构成了目前市面上各个大模型之间差异化的区别。
AI解决了什么
我个人认为对于普通人,解决最大的问题就是信息鸿沟,普通人获取一个知识,需要不停的查阅很多文档资料,同时还要区分真假,甚至还可能要进行理解前的知识准备,而AI则可以利用学习到的这些知识对查询的知识进行甄别、研判以及总结,以一种让普通人更容易理解的方式产出信息,所以我觉得AI是众多科学家通过在多年积累,送给普通人一个信息平等的“认知红利”。
AI为什么需要管控
那么既然AI这么好,为什么国家还需要对AI进行管控?目前几乎所有常听见的模型都是由开发模型的公司管理用户的数据,比如ChatGPT所属OpenAI、Deepseek所属深度求索公司、Gemini所属Google公司,那么既然由公司管理,肯定也就会存在数据泄露,比如某个员工将企业的数据或者文档上传到某个大模型,而后大模型使用用户的数据进行训练,其他人就可以间接得到这份数据的内容。
但是还有一些深层的考虑,往后的时间内,很有可能普通人是通过AI工具进行数据的检索和获取(替代搜索引擎),那么基于这样的环境下,如果一个公司掌握了诸多不同身份的使用者的语料(输入的内容),就可能存在针对用户进行画像。
“画像”可以简单理解为这个人住哪里,喜欢吃什么?喜欢去哪里?是否有孩子?在哪里上班?职位大概是什么?类似刑侦调查中通过一些证人去描述犯罪嫌疑人的特征,进一步画像出嫌疑人的面部,而数据也是这样,通过你在虚拟世界中的行为、数据去画像映射出你在现实生活中的样子(特征)。
无害的利用可能会应用在商业活动,如广告、商品的推送,有害的利用,则在深层上,会存在一些严重的问题,比如针对关键人员以及军工人员等特殊群体进行针对性的画像,进一步实施破坏,对政府会造成非常严重的影响。
投资实录
从2025年4月重新开始,我将该计划称为“极光计划”,预计每年争取在7%及以上的收益率,这个收益并不代表年年都在范围内,而是看整个投资周期的收益,所以别杠。
实证我在每个月15号之前进行更新,主要记录上个月的情况,截至目前收益率为0.36%。
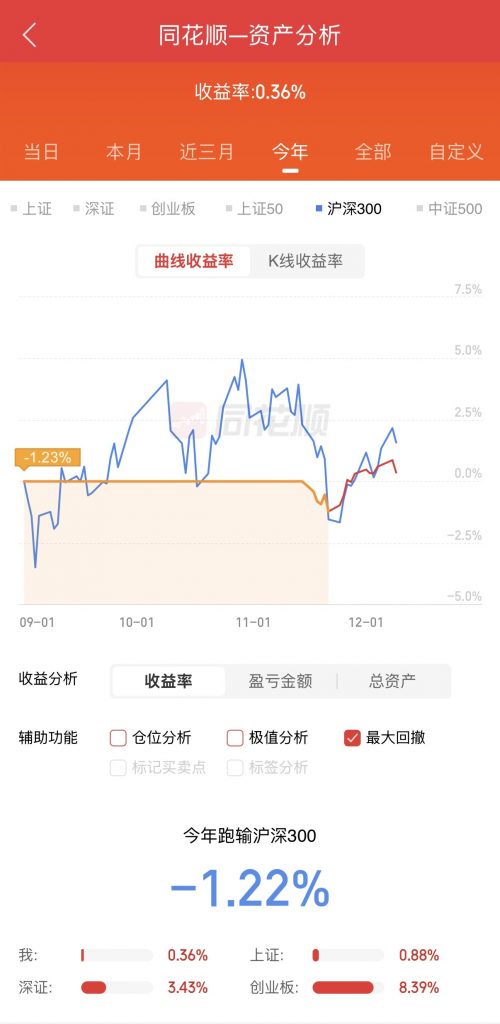
收益率这么低的原因是因为两个原因,原因一是目前我换了一个券商,券商我由以前的招商换到了银河,主要原因是因为银河可以作为三方券商接入到同花顺平台,各位也可以去下载一个同花顺,看看自己的券商是否能接入,整体上同花顺的各类信息、便利程度都要比招商的高。原因二则是对比的幅度为当前一年。
发表回复